業務にAIを活用する際、「社内の情報に基づいた正確な回答が欲しい」「最新の情報を反映した回答を得たい」というニーズが高まっています。しかし、LLM(大規模言語モデル)は学習データが限られており、社内固有の情報や知見を自ら把握することはできません。
このような課題を解決する方法として注目を集めているのが、RAG(検索拡張生成)です。本記事では、RAGの仕組みから検索精度を左右する要因、実際の活用例などを網羅的にわかりやすく解説します。
- 目次
RAGとは
RAG(検索拡張生成:Retrieval-Augmented Generation)とは、AIが回答を作成する前に外部の知識ソースを検索して根拠となる情報を集め、その情報をもとに回答を生成するアーキテクチャのことです。「Retrieval(検索)」「Augmented(拡張)」「Generation(生成)」の頭文字を取ったもので、「ラグ」と読むのが一般的です。
LLM単体では、学習済みデータの範囲内でしか回答を生成できないため、社内文書や最新の業界動向など、学習データに含まれない情報への対応は困難です。しかし、RAGはこの制約を補い、LLMを再学習させることなく、特定のドメインや企業固有の知識に基づいた回答を実現する仕組みとして、多くの企業で導入が進んでいます。
RAGの仕組み
まずは「なぜRAGという仕組みが有効なのか」という原理を整理しておきましょう。RAGの仕組みを理解することで、技術的な内容がよりスムーズに頭に入ってきます。
ことばの意味を座標として捉える
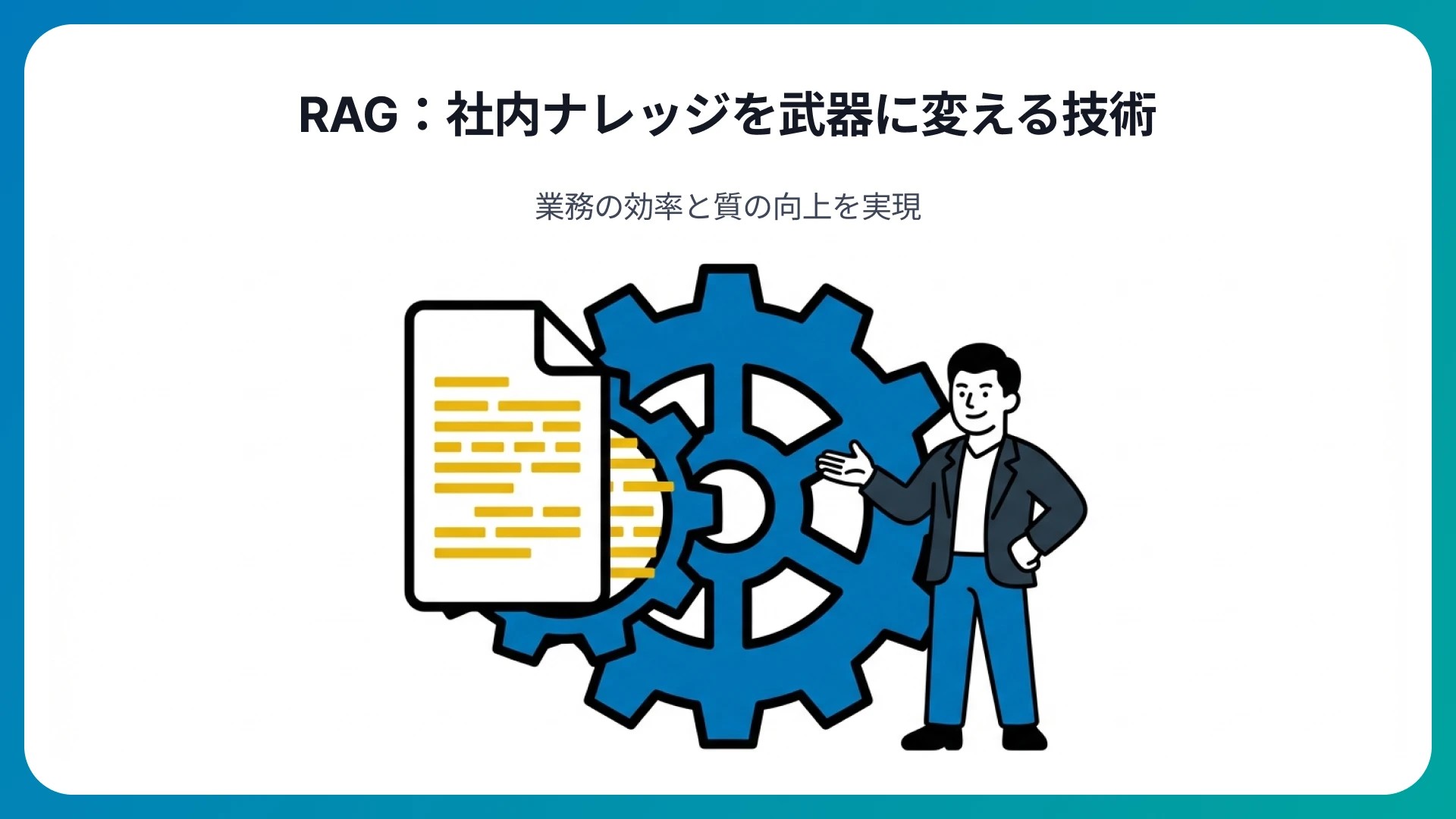
RAGにおいて最も重要な技術的土台は、ことばの意味をベクトル(数値)に変換するプロセスです。コンピュータはことばの意味をそのまま理解することはできません。しかし、ことばを多次元空間上の座標として数値化すれば、数学的な計算が可能になります。
この多次元空間では、「意味の近いことば同士は近くに、意味の遠いことば同士は遠くに配置される」という特徴があります。たとえば、「犬」と「猫」は近くに配置されますが、「犬」と「電車」は遠く離れた場所に位置付けられるといった具合です。
ユーザーから質問が届いた際、RAGはこの座標を使って「質問の意味に最も近い情報」をナレッジベースから瞬時に探し出します。この意味の近さで情報を検索する仕組みが、単純なキーワード一致に頼らない柔軟な情報取得を実現しているのです。
情報の「暗記」ではなく「カンニング」

LLMの仕組みは、しばしば「非常に物知りな人」に例えられます。しかし、LLMが持っている知識は、学習時点の古い情報であったり、細かい数値までは正確に学習していなかったりすることが少なくありません。
そこでRAGは、LLMに「暗記で答えること」を強いるのではなく、「試験会場に最新の参考書を持ち込ませる」ようなアプローチを採用しました。具体的には、質問に関連する社内資料や最新ニュースをカンニングペーパーとして、プロンプトに動的に挿入します。LLMは与えられた資料をその場で読み込み、そこに書かれている事実に忠実な回答を作成すれば良いため、ハルシネーションのリスクを大幅に低減できるのです。
AIとデータを結びつけるシステム

AIの回答を外部の確かな事実情報に結びつけるプロセスは「グラウンディング」と呼ばれています。RAGは単なる検索ツールではなく、「AIの高い知能」と「外部の信頼できるデータ」の橋渡しを行うシステムだと言えるでしょう。
プロンプト内で「以下の資料のみを根拠に答えてください。資料にないことは『わかりません』と回答してください」という指示を与えることで、AIの回答範囲を厳格に制限できます。この「事実への設置(グラウンディング)」という設計思想こそが、RAGがビジネスシーンで高く評価される最大の理由です。
RAGを活用したAIエージェント「うちのAI」

「うちのAI」は、高度なRAG技術をノーコードで活用できる、企業向けのAIエージェントサービスです。
ここまで解説した「ベクトル検索」や「グラウンディング」といった複雑なRAGの仕組みを意識することなく、お手持ちのドキュメント(PDFやテキストなど)をアップロードするだけで、企業のコンテキストを深く理解した自社専用のAIを簡単に構築できるのが特徴です。
「うちのAI」のサービスラインナップ
うちのAI Chat
「うちのAI」の中で最もスタンダードなRAG活用サービスです。直感的なインターフェースを通じて、社内規程やマニュアルといった膨大なナレッジから正確な根拠に基づいた情報を瞬時に引き出します。社内問い合わせの自動化や、ナレッジの属人化解消において即戦力となるサービスです。
うちのAI Avatar
RAGによる正確な情報提供に加え、「ビジュアル」と「音声」を融合させた次世代のAIアバターサービスです。Webサイトでの接客、店舗の案内サイネージ、受付対応などをブランドイメージに合わせたアバターやキャラクターを通じて、より親しみやすく、より記憶に残るコミュニケーション体験を提供します。
\ 実際に『うちのAI Avatar』を使えます/
下の画像をクリックすると、「うちのAI」の情報を学習した『うちのAI Avatar』がご利用いただけます。ぜひお試しください!

RAGの精度が変わる要因
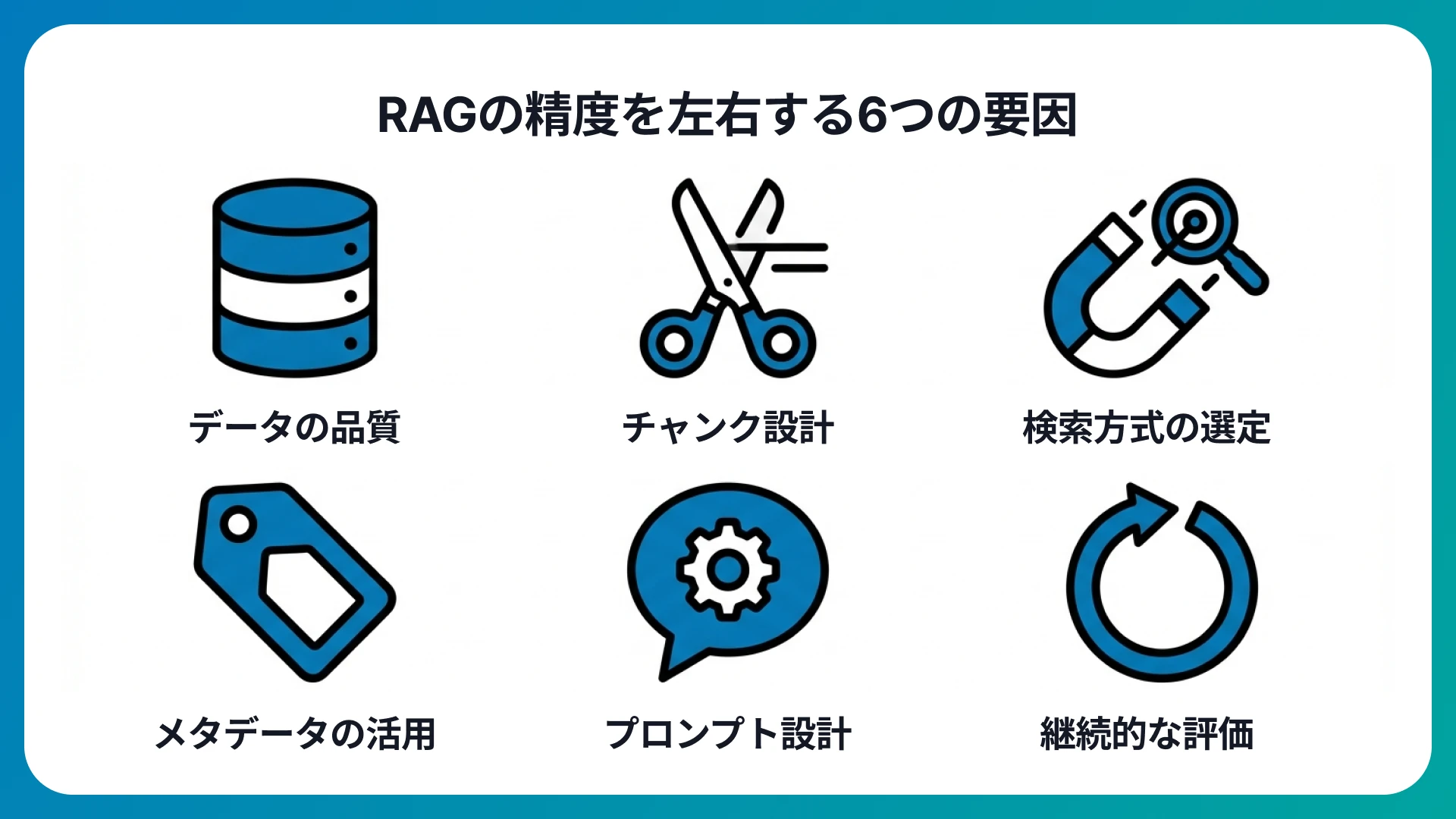
RAGの回答精度は一様ではなく、設計や運用のあり方によって大きく変動する点に注意が必要です。精度に影響を与える要因の理解が、RAGの効果を最大限に引き出すために重要だと言えます。
検索と生成の品質を分けて考える
RAGの精度は「検索の品質」「生成の品質」の2つの品質で構成されています。
| 品質の種類 | 評価の観点 |
|---|---|
| 検索の品質 | 質問に対して適切な根拠が取得できているか |
| 生成の品質 | 取得した根拠に沿って正確に回答しているか |
検索の段階で適切な情報取得ができていなければ、どんなにLLMが優秀であっても正確な回答にはつながりません。「検索が外れると、回答も外れる」というRAGの構造を押さえておくことが重要です。
精度を左右する主要な要因
RAGの精度を左右すると言われている主な要因は、以下の表のとおりです。
| 要因 | 概要 |
|---|---|
| データの品質 | 「情報が古い」「情報に誤りがある」「データの重複が多い」場合、検索精度が大幅に低下する |
| チャンク設計 | チャンクが長すぎるとノイズが増え、短すぎると文脈が失われてしまう |
| 検索方式の選定 | キーワード検索、ベクトル検索、両者を組み合わせたハイブリッド検索など、用途に応じた検索方式の選択 |
| メタデータの活用 | 部署名や製品カテゴリ、日付などのメタデータで検索範囲を絞り込むと精度が改善する傾向にある |
| プロンプト設計 | 「根拠にない情報は回答しない」「不明な場合は不明と答える」といった制御指示 |
| 継続的な評価 | 運用開始後も定期的にスコアリングと改善を繰り返す体制の構築 |
RAGのメリット・デメリット
たしかにRAGは検索精度を大きく向上させる技術ですが、決して万能ではありません。RAGの導入に際しては、メリットとデメリットの双方を正しく把握しておく必要があります。
RAGのメリット
RAGの導入で得られるおもなメリットは、以下の3点です。
- 再学習なしで知識を更新できる
- 社内固有のデータを回答材料にできる
- 根拠の提示で信頼性が向上する
再学習なしで知識を更新できる

ナレッジベースのドキュメントの差し替えだけで情報更新ができるため、LLM自体を再学習させる必要がありません。運用コストと時間の大幅な短縮につながります。
社内固有のデータを回答材料にできる
LLMが学習していない社内規程やマニュアル、顧客対応履歴などの社内データも検索対象に含められるため、特定の業務に特化した回答の生成が可能になります。
根拠の提示で信頼性が向上する
回答生成時に「どの文書のどの部分を根拠にしたか」を併せて提示できるため、回答の検証も容易に行えます。とくにコンプライアンスが重視される金融・医療業界では、説明可能性の確保が導入判断を後押しする大きな要因となっています。
RAGのデメリット
メリットの一方で、RAGの導入にはデメリットも存在します。導入前にデメリットも同時に把握しておくことで、リスクを最小限に抑えられます。
- 検索が外れると回答精度も下がる
- レイテンシとコストの増加
- セキュリティと権限設計が不可欠
- ナレッジの鮮度は自動で保証されない
検索が外れると回答精度も下がる

検索段階で不適切な情報を取得してしまうと、LLMは誤った根拠に基づいて回答を生成しかねません。「Garbage in, garbage out(ゴミを入れたら、ゴミが出てくる)」の原則はRAGにも当てはまるため、ナレッジベースの品質管理が必要です。
レイテンシとコストの増加
LLM単体の推論に加えて、追加で検索処理や再ランキングが発生するため、応答時間とAPI利用コストが増加する傾向にあります。リアルタイム性が求められるユースケースでは、レスポンス速度の最適化が課題として挙がるでしょう。
セキュリティと権限設計が不可欠
社内の機密文書をナレッジソースとして利用する場合、アクセス制御やログ管理、情報漏洩対策を徹底しなければなりません。RAGの技術的な側面だけでなく、運用ルールの整備が導入成功のカギを握ります。
ナレッジの鮮度は自動で保証されない

ナレッジベースの更新が滞ると、古い情報や誤った情報がそのまま回答に反映されてしまうおそれがあります。定期的なデータ更新体制を組織的に構築することが必要です。
RAGの活用事例
RAGはすでに多くの企業で導入が進んでおり、業種を問わず幅広い場面で成果を上げています。国内外の代表的なRAGの活用事例を紹介します。
金融業界:Morgan Stanley(モルガン・スタンレー)
OpenAIの事例として紹介されている「AI @ Morgan Stanley Assistant」は、RAGを活用した社内向けチャットボットです。10万件を超える社内文書をナレッジベースとして構築し、アドバイザーが必要な情報を瞬時に検索・取得できる仕組みを実現しました。アドバイザーチームの98%以上が日常的に利用しているとされ、大量の社内ナレッジを啓作して回答できるRAGの典型的な成功パターンだと言えるでしょう。
参考:モルガン・スタンレーは、AI eval を活用して金融サービスの未来を形作ります | OpenAI
製薬・調査業界:IQVIA サービシーズ ジャパン
AWS公式ブログで紹介されている事例として、IQVIAサービシーズ ジャパンの取り組みがあります。同社は、Amazon Bedrockのナレッジベースを用いたRAGベースのAIチャットを構築し、専門性の高い業界知識を効率的に共有するための基盤としてRAGを役立てています。
エンタメ・ゲーム業界:スクウェア・エニックス
Microsoftの顧客事例では、スクウェア・エニックスの社内向けAIアシスタント「Hisui-chan」のアーキテクチャとして、Azure AI Searchを用いたRAG構成が採用されたことが明かされました。ゲーム開発という専門性の高い領域で、社内ナレッジの検索と回答生成を自動化した好例です。
参考:Square Enix uses Azure OpenAI Service for AI-enhanced game development | Microsoft Customer Stories
さまざまな国内企業の導入事例
日本国内でもRAGの活用は急速な広がりを見せており、業種を問わず多くの企業が導入を進めています。
| 企業名 | 活用内容 |
|---|---|
| 三井住友カード | 月間約50万件の問い合わせ対応にRAGを導入し、回答草案の自動生成で対応時間を最大60%短縮 |
| LINEヤフー | 全従業員向けツール「SeekAI」にRAGを実装し、社内データを参照した最適な回答を提供 |
| ライオン | 技術知見を蓄積したRAG基盤を構築し、研究員の「知識伝承のAI化」を実現 |
| AGC | 社内向け生成AI環境「ChatAGC」にRAG技術を導入し、社内データの利活用を促進 |
| NEC | 社内向け生成AIサービス「NGS」にRAG技術(LlamaIndex)を採用し、推論精度を向上 |
このように、金融・製造・通信・化学など、業種や規模を問わずRAGの導入が現在加速しています。2026年にはRAGがAI活用の前提技術として定着し、さらに高度なAIエージェントやワークフローとの連携へと発展する見通しです。
参考:三井住友カードとELYZA、お客さまサポートにおける生成AIの本番利用を開始、LINEヤフー、RAG技術を活用した独自業務効率化ツール「SeekAI」を全従業員に本格導入。、生成AIと検索システムを用いた「知識伝承のAI化」ツールの開発を開始、自社向け生成AI活用環境「ChatAGC」に、社内データ連携機能を付与、生成AIの社内活用を進めるNEC Generative AI Service
RAGの導入で業務の効率と質の向上を実現
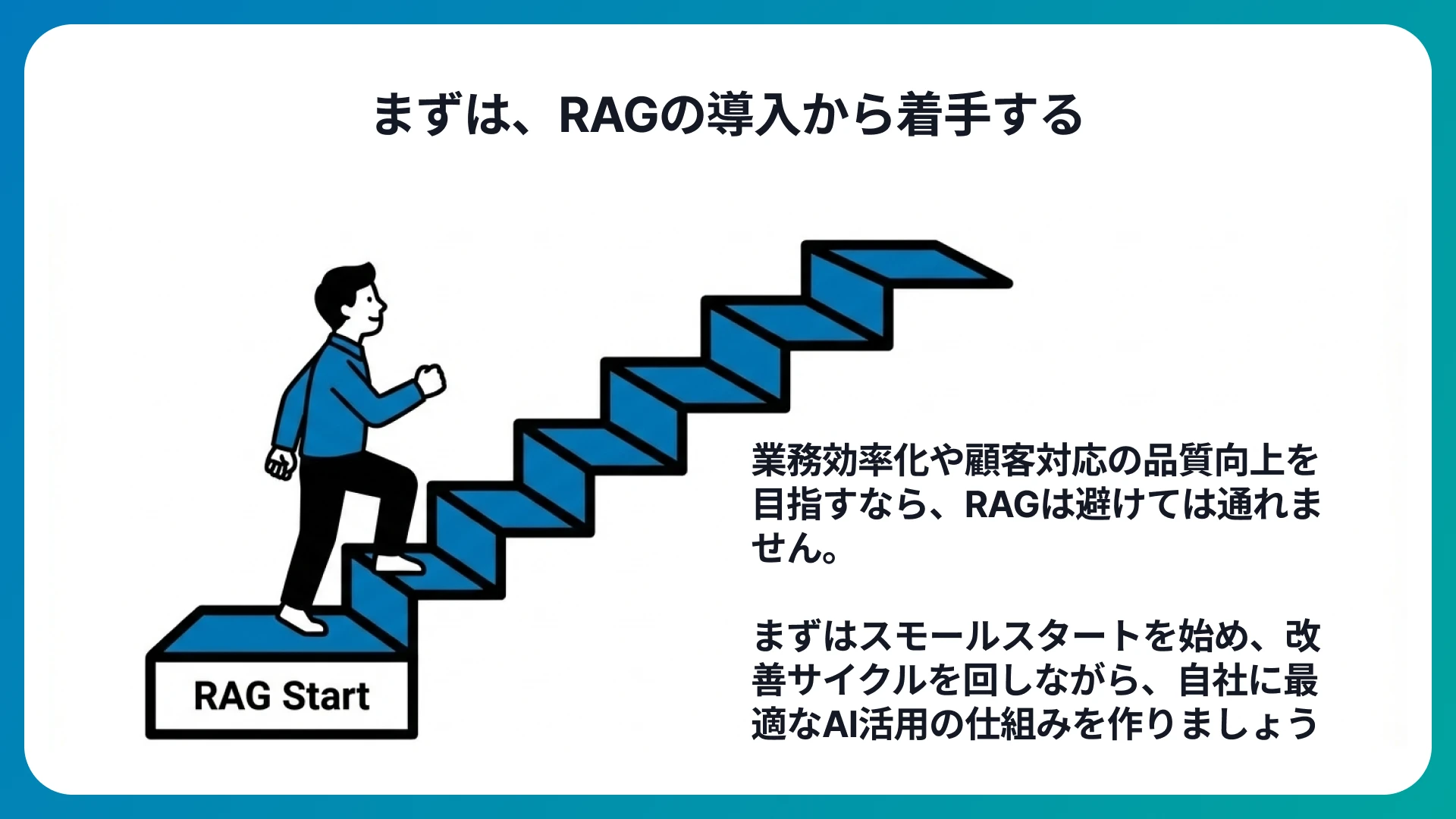
RAG(検索拡張生成)は、LLMの「固定知識」と「コンテキストの有限性」という制約を補い、外部の知識ソースに基づいた正確な回答を実現する仕組みです。再学習なしで社内固有の情報に対応しやすく、根拠の提示による信頼性の向上も期待できるため、企業のAI活用において欠かせない技術となりました。
一方で、検索精度やデータの鮮度、システムの複雑性といった課題も存在するため、継続的な評価と改善のサイクルを回す運用体制が求められます。RAGの精度を左右する要因を正しく理解し、データ品質やチャンク設計、プロンプト設計などを継続的に見直していくことで、RAGの効果を最大限に引き出せるでしょう。
本記事で紹介したように、国内外の多くの企業がすでにRAGを導入し、社内ナレッジの検索や問い合わせ対応の効率化を実現しています。自社の業務効率化や顧客対応の品質向上にAIの活用を検討している方は、まずRAGの導入から着手してみてはいかがでしょうか。
RAG関連記事
 「うちのAI」トップページ |
|
| 資料ダウンロード | お問い合わせ |
施設でのエージェント活用



業務でのAIエージェント活用





AI関連用語 解説記事
| 用語解説 | ||
| RAG(検索拡張生成) | ||